[1] 4Introducción al análisis de datos con R
Curso dirigido a Ciencias Sociales y Humanidades
¿Qué es R?
R es un lenguaje de programación enfocado al análisis de datos, las estadísticas y la visualización de datos.
![]()
¿Para qué sirve?
- Lógica distinta: instrucciones en vez de acciones ⚙️
- Repetir, mejorar, adaptar y reutilizar lo que ya has hecho ♻️
- Automatizar tareas repetitivas 🤖
- Expandir tus resultados 🚀
¿Qué se puede hacer con R?

Muestra de algunas aplicaciones, gráficos, tablas, y mapas hechos con R. También algunos trabajos que he hecho.
Diferencia entre R y RStudio
R
![]()
- Lenguaje de programación
- Lanzado en 1993
- Usado por línea de comandos
- Desarrollado por R Core Team
- Basado en el lenguaje S (1976)
- Software libre
RStudio
![]()
- Entorno de desarrollo integrado (IDE) enfocado en R
- Lanzado en 2011
- Interfaz gráfica (ventanas y botones)
- Desarrollado por Posit (ex RStudio)
- Software libre
Conceptos clave

Script
Archivo de texto .R en el que escribimos nuestro código, en pasos, y siguiendo un orden lógico.

Consola
Es la forma directa de interactuar con R, un comando a la vez, con resultados efímeros.

Proyecto
Archivo .Rproj que marca nuestro espacio de trabajo: una carpeta específica que reúne todas las piezas de nuestro análisis.
RStudio
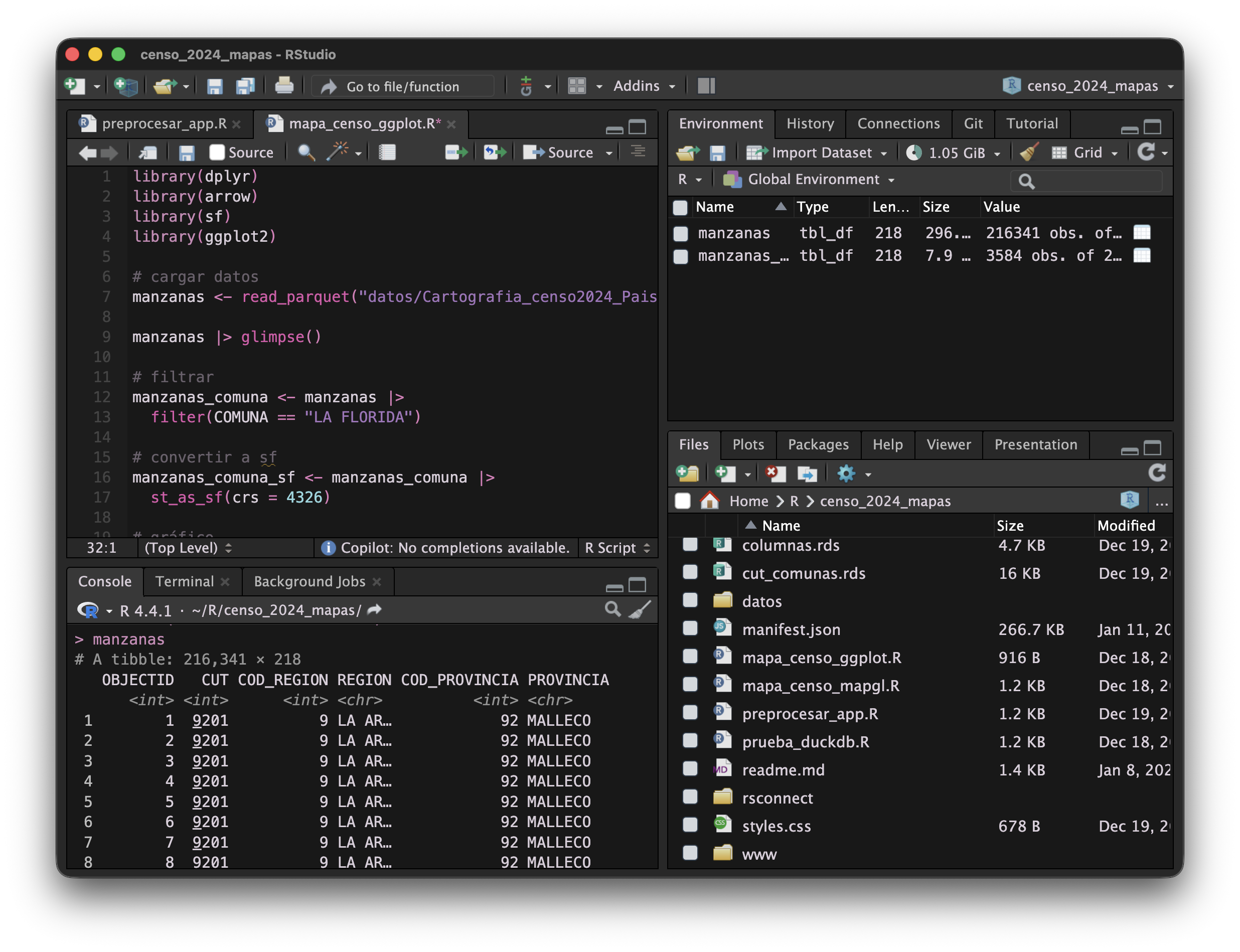
1 Scripts
2 Consola
3 Entorno
4 Archivos
Consola y scripts
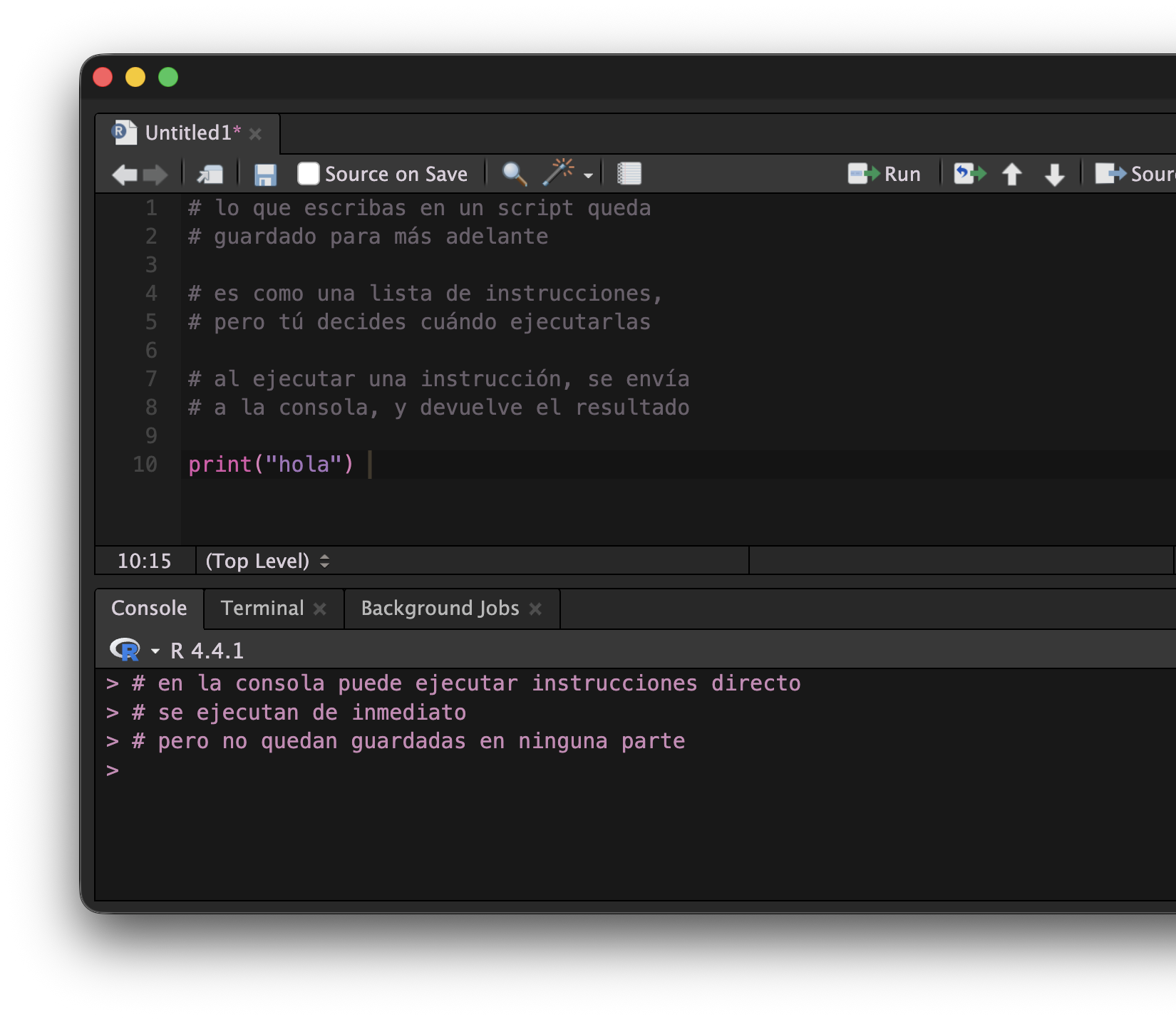
- Todos los comandos se ejecutan por medio de la consola
- Pero al ejecutar código en la consola, el código no se guarda!
- Para guardar el código, escribimos en scripts
- Escribimos las instrucciones en un script, y RStudio se encarga de pasarlos a la consola y ejecutarlos cuando se lo pidamos 💡
Botones
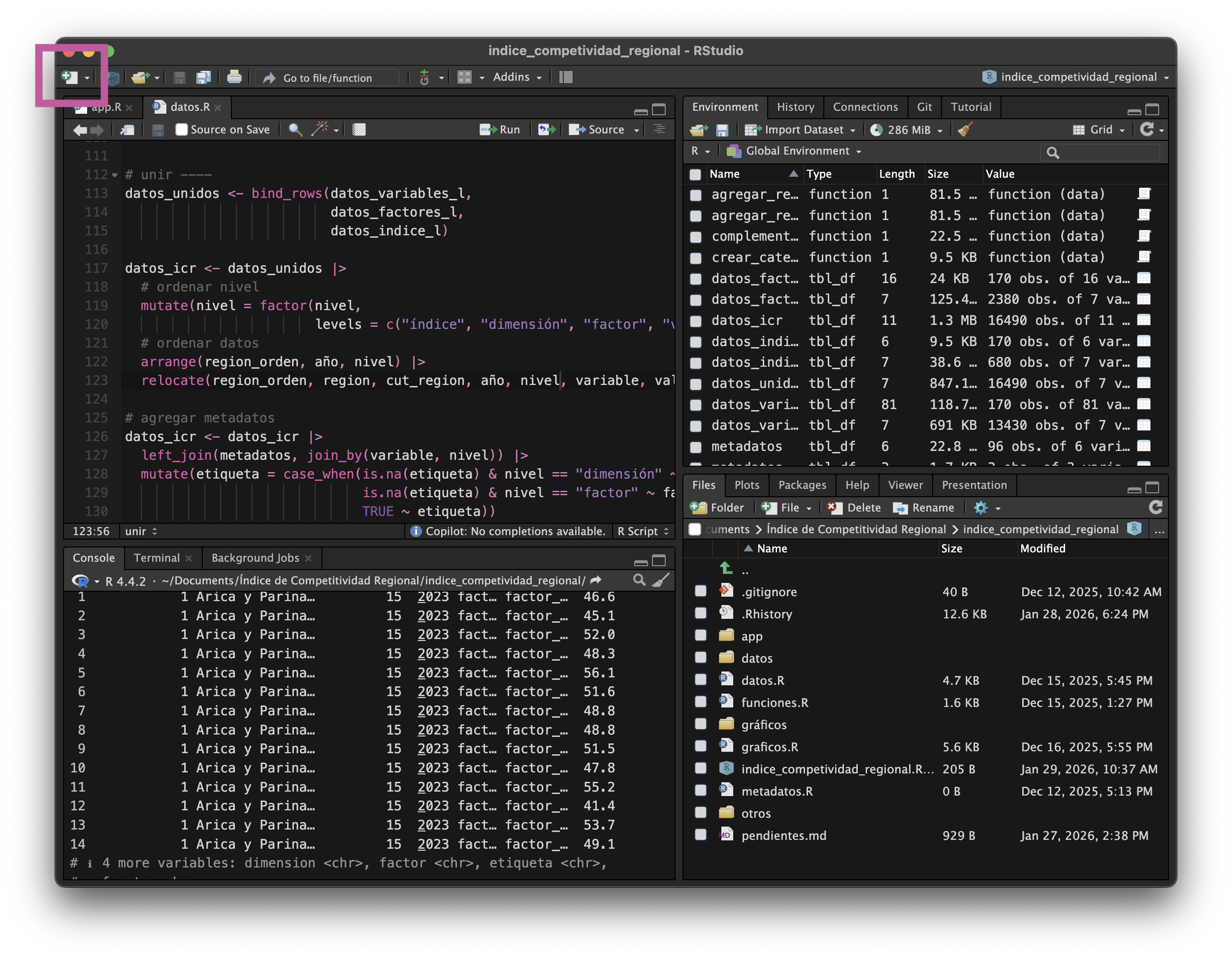
Crear un nuevo script de R
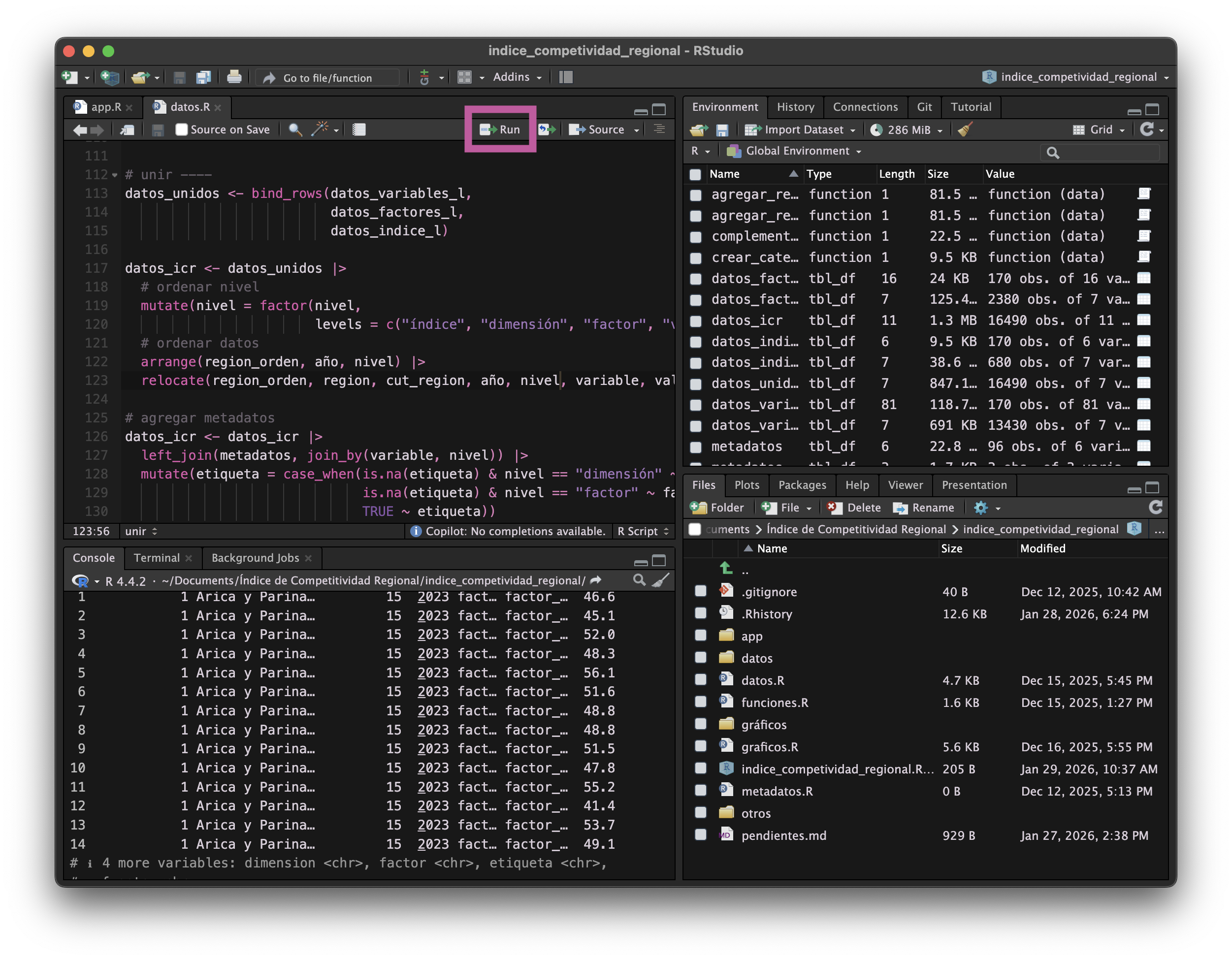
Botón para ejecutar código
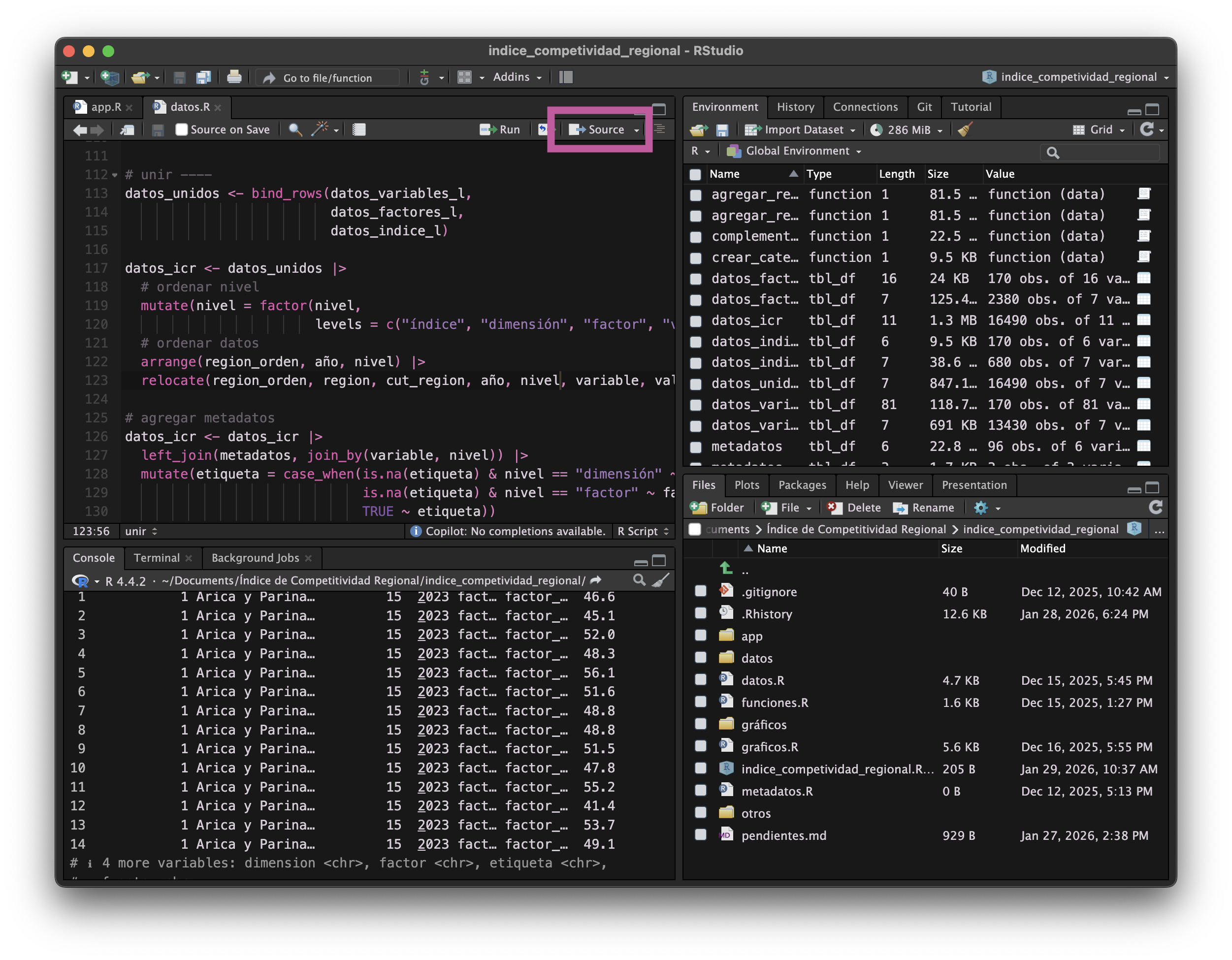
Botón para ejecutar todo el script
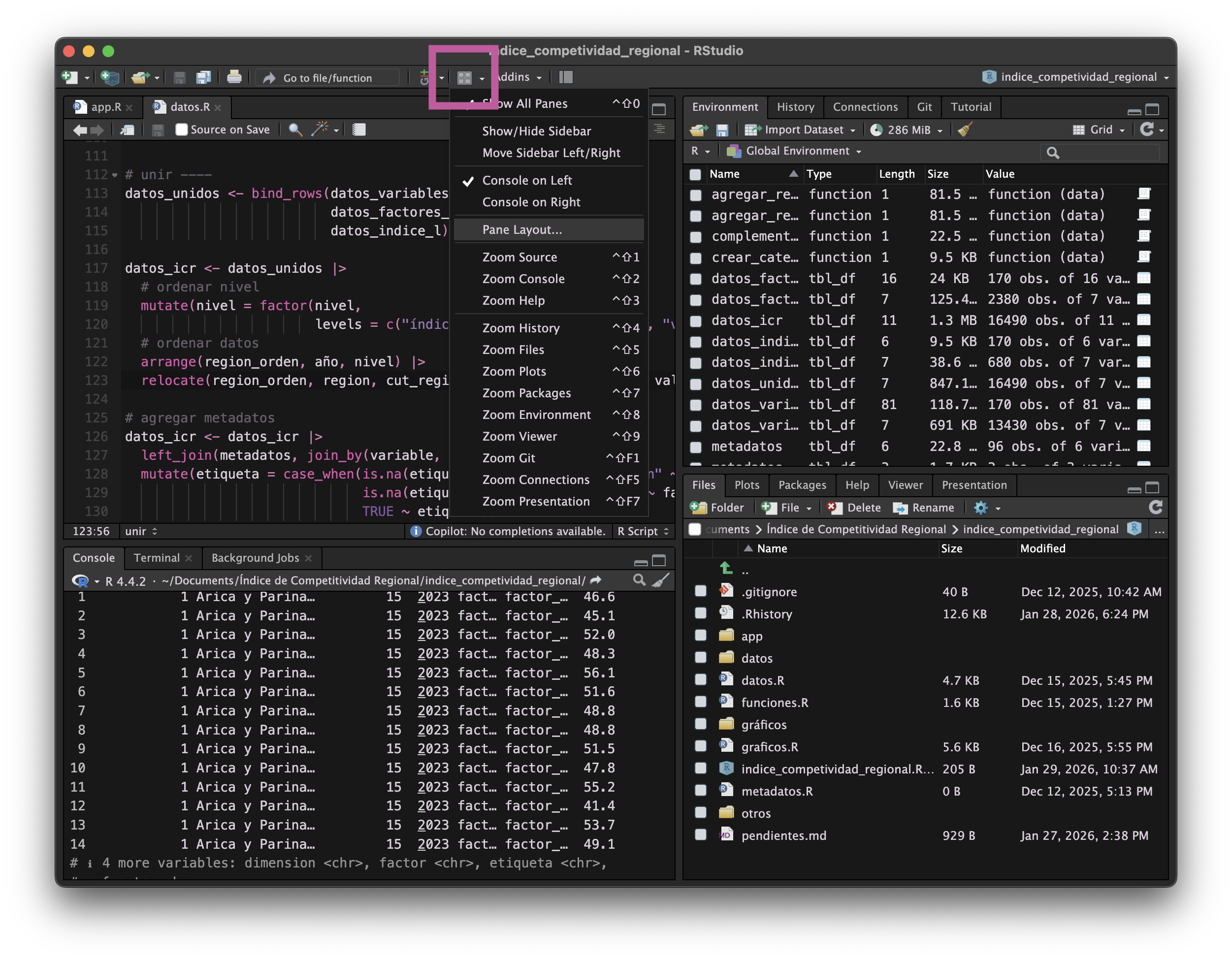
Configurar paneles de RStudio
Cambiar de proyecto o crear uno nuevo
Asignación
Con el operador de asignación creamos objetos nuevos.
->
Se escribe con:
Windows:

Mac:
Paquetes
- Extensiones de R que te permiten agregar nuevas y mejores funcionalidades.
- Se instalan desde internet
- Son creados y mantenidos por la comunidad
- Se revisan para garantizar su seguridad y estabilidad
install.packages()Paquetes para carga de datos

{readxl}es uno de los paquetes de lectura de planillas Excel. Para escribir un archivo Excel está{writexl}{readr}lee y escribe datos de múltiples formatos (csv, rds, rdata), usualmente de forma más veloz y cómoda{haven}permite cargar archivos SPSS, Stata, y SAS{arrow}es un formato moderno de datos columnares, optimizado para grandes volúmenes y velocidad de carga, y pensado para usarse en distintos softwares
{dplyr}
- Paquete de exploración, manipulación y transformación de datos
- Sus funciones se escriben como verbos
- Las acciones se encadenan con el operador de conexión o pipe:
|>

Conector
El conector o pipe |> (o también %>%) nos permite encadenar varias funciones de forma más legible.
|> %>%
Se escribe con:
Windows:

Mac:

Datos de texto

El paquete {stringr} se especializa en texto.
Cruzar datos
Para cruzar dos tablas de datos
usamos left_join() de {dplyr}

Transformando datos

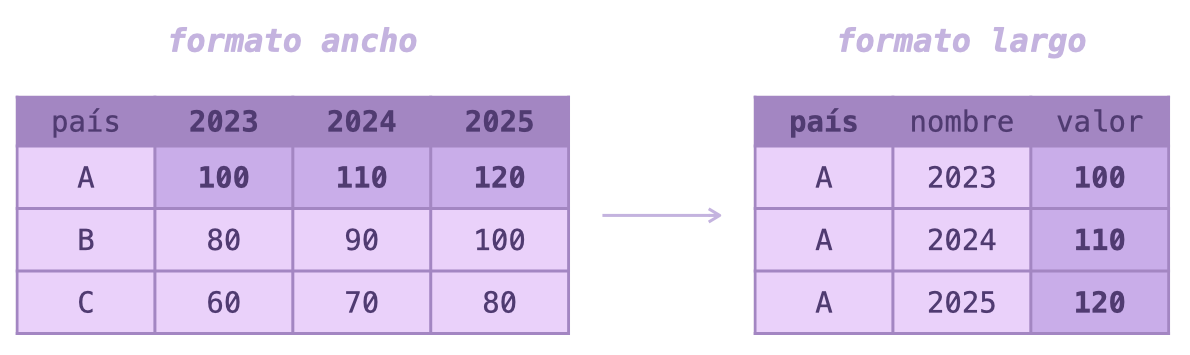
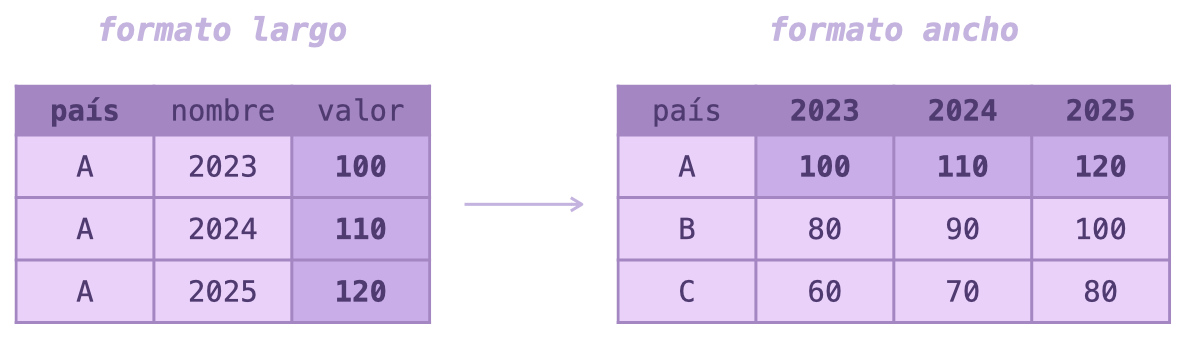
- Pivotar una tabla sirve para cambiar su forma:
- De variables en columnas a filas:
pivot_longer() - De variables en filas a columnas:
pivot_wider()
- De variables en columnas a filas: